قالب های فارسی وردپرس 3
این وبلاگ جهت دسترسی آسان شما عزیزان به قالب های برتر وردپرس به صورت فارسی تدوین و راه اندازی شده است.قالب های فارسی وردپرس 3
این وبلاگ جهت دسترسی آسان شما عزیزان به قالب های برتر وردپرس به صورت فارسی تدوین و راه اندازی شده است.کسب و کارهای آنلاین
افزایش بازدید سایت یگانه از اصلی ترین کارهایی است که هر صاحب سایتی باید به آن اهمیت دهد. به راستی اگر شما صاحب هر سوداگری آنلاینی هستید باید در صدد بالا بردن بازدید سایت خود باشید. فرقی نمی کند چه خدمات و محصولاتی را ارائه می کنید، در هر صورت باید به اندیشه بالا بردن بازدید سایت تان باشید. کاملا مشخص است که شدامد هر سایتی جزئی از سرمایه آن است.
هر چقدر که تارنما شما از هر لحاظی عالی باشد تا زمانی که نتوانید ترافیک راستین اخذ کنید بی فایده است و هیچ سودی برای شما نخواهد داشت.
دلیل عمده بسیاری از کسب و کارهای آنلاینی هم که موفق نیستند نداشتن ترافیک کافی است. همین اکنون که وب سایت هایی وجود دارند که از هر لحاظی با کیفیت هستند ولی سخت اصلی آن ها دیده شدن است. در واقع مدیران این سایت ها در بالا بردن شدامد سایت شان لاغر هستند و نمی توانند به احسان روزانه ترافیک واقعی و هدفمندی را روانه سایت خود کنند.
در این مقاله هدف دارم تکنیک های کسب ترافیک بیشتر را به شما شناسایی کنم لغایت به راحتی بتوانید شدامد واقعی و هدفمندی را به سایت خویش جذب کنید. روش هایی که در این نوشتار گفته می شود اکثرا بر اساس فرآوری محتوای هدفمند هستند و هر کدام به انفرادی می تواند چندین برابر بازدید سایت شما را افزایش دهد. فقط کافی است به آن ها عمل کنید لغایت از جذب ترافیک هدفمند بالا لذت ببرید.
پس اگر شما هم دانستن می کنید در افزایش بازدید سایت تان سخت دارید در این مقاله جامع به اتفاق من باشید. به شما قول می دهم با خواستن این نوشتار خرج کردن های اضافی برای افزایش بازدید سایت تان را به کلی فراموش خواهید کرد.
چگونه اطلاعات ویکی پدیا را استخراج و تحلیل کنیم؟
غنای اطلاعات ویکیپدیا بر هیچکس پوشیده نیست. از دریای اطلاعات این وبسایت میتوان برای تحقیقهای تجاری و غیرتجاری و تقریبا در هر زمینهای بهره برد. شرکتها، محققان، دانشمندان داده و حتی افراد صرفا کنجکاو، همهوهمه درزمرهی افرادی قرار میگیرند که سعی میکنند دادههای ویکیپدیا را استخراج و تحلیل کنند.
ویکیپدیا بهمثابهی گنجینهای است که از مجموعهای از صدهامیلیون صفحهی وب و میلیونها مقالهی وزین چندزبانه تشکیل شده است. این امر ویکیپدیا را به بهشت خزندگان وب (Web Crawler) تبدیل کرده است. با جستوجویی ساده در گیتهاب، متوجه میشوید بیش از سیصد خزندهی وب و پروژههای مشابه برای استخراج داده از ویکیپدیا وجود دارد.
مقالههای مرتبط:
وبکراولینگ، تنها راه موجود برای استخراج و تحلیل دادههای ویکیپدیا نیست. برای مثال، ویکیمدیااجازهی استخراج دادهها در فرمتهای متنوعی را میدهد. همچنین، API ویکیمدیا نهتنها برای دریافت اطلاعات، بلکه برای ایجاد باتها و تعامل با مقالات بهطور برنامهنویسیشده استفاده میشود.
در آموزش زیر، روی ابزار Mixnode تمرکز میکنیم که استخراج و تحلیل دادهها از ویکیپدیا با استفاده از کوئریهای SQL را فراهم میآورد. برای استفاده از این ابزار باید با SQL آشنا باشید.
Mixnode چگونه کار میکند؟
Mixnode اجازه میدهد با وب مانند پایگاه داده برخورد کنید. با استفاده از Mixnode میتوانید کوئری بنویسید و آن را روی وب اجرا کنید. با اجرای کوئری مدنظر Mixnode بهطور خودکار صفحات لازم برای پاسخ به کوئری را پیدا میکند.
مثالهای زیر نحوهی کارکرد Mixnode و استخراج و تحلیل دادهها را شفافتر میکند.
مثال ۱: بهدستآوردن آدرس تمامی صفحات ویکیپدیا
select
url
from
pages
where
url_domain = 'wikipedia.org' - متغیر
urlنمایانگر آدرس صفحه است pagesجدولی است که هر ردیف آن مطابق با صفحهی منحصربهفرد در وب است- با
url_domain = 'wikipedia.org'مطمئن میشویم که فقط صفحات ویکیپدیا و سابدامینهای آن (مانندen.wikipedia.org) مدنظر قرار میگیرند. اگر بخواهید فقط در ویکیپدیای فارسی جستوجو کنید، کافی است عبارتfa.wikipedia.orgرا جایگزین کنید.
مثال ۲: بهدستآوردن آدرس و عنوان تمامی مقالات ویکیپدیا
select
url,
css_text_first(content, 'h1#firstHeading') as title
from
pages
where
url_domain = 'wikipedia.org'
and
url like '%/wiki/%'css_text_first(content, 'h1#firstHeading')عنوان مقالهی ویکیپدیا را خروجی میدهد. با نگاهی به سورس HTML مقالات ویکیپدیا، پی میبریمh1#firstHeadingمسیر CSS برای عنوان مقاله است.css_text_firstنیز تابعی است که اجازهی استخراج اولین مورد از انتخابگر CSS را میدهد. content در اینجا سورس کامل HTML صفحه است.- ازآنجاییکه قصد داریم عناوین مقالات را بهدست آوریم و میدانیم در آدرس مقالات ویکیپدیا از /wiki/ استفاده میشود، از
url like '%/wiki/%'استفاده میکنیم تا مطمئن شویم نتایجمان فقط به مقالات مربوط میشود.
مثال ۳: بهدستآوردن عناوین تمامی مقالات شامل زیررشتهی Elon Musk
select
url,
css_text_first(content, 'h1#firstHeading') as title
from
pages
where
url_domain = 'wikipedia.org'
and
url like '%/wiki/%'
and
contains(content, 'Elon Musk')contains()تابعی است که اجازهی بررسی وجود یک زیررشته در یک رشته را میدهد. با استفاده ازcontains(content, 'elon musk')مطمئن میشویم که در نتایجمان عبارت Elon Musk موجود است.
مثال ۴: مرتبسازی مقالات ویکیپدیا براساس تعداد ارجاعات
select
url,
css_text_first(content, 'h1#firstHeading') as title,
cardinality(css_text(content, 'ol.references li')) as reference_count
from
pages
where
url_domain = 'wikipedia.org'
and
url like '%/wiki/%'
order by reference_count desc- بررسی کد منبع یک مقالهی ویکیپدیا نشان میدهد تمامی ارجاعات و منابع با انتخابگر
ol.referencesقابلدسترسی است.css_text(content, 'ol.references li')متن تمامی منابع مقاله را به ما میدهد و ازآنجاییکه فقط به تعداد نیاز داریم، پس از تابعcardinality()استفاده میکنیم که اندازهی یک آرایه را برمیگرداند. desc در خط آخر مقالات را بهصورت نزولی برایمان مرتب میکند. برای مرتبسازی بهصورت صعودی از asc استفاده کنید.
مثال ۵: مرتبسازی مقالات ویکیپدیا براساس طول مقاله
select
url,
css_text_first(content, 'h1#firstHeading') as title,
cardinality(words(css_text_first(content, '#content'))) as article_length
from
pages
where
url_domain = 'wikipedia.org'
and
url like '%/wiki/%'
order by article_length descwords()آرایهای شامل تمامی کلمات یک متن را برمیگرداند. استفاده ازcardinality(words(css_text_first(content, '#content'))) as article_length، تعداد کلمات یک مقاله را به ما میدهد.
مثال ۶: اندازهی میانگین یک مقالهی ویکیپدیا
select
avg(cardinality(words(css_text_first(content, '#content')))) as average_article_length
from
pages
where
url_domain = 'wikipedia.org'
and
url like '%/wiki/%'- تابع
avg()میانگین دادههای ورودیاش را برمیگرداند که در اینجا، تعداد کلمات تمامی مقالات ویکیپدیاست.
مثال ۷: مرتبسازی مقالات ویکیپدیا براساس بحثهای آن
select
url,
remove_left(css_text_first(content, 'h1#firstHeading'), 'Talk:') as title,
cardinality(words(css_text_first(content, '#content'))) as discussion_length
from
pages
where
url_domain = 'wikipedia.org'
and
url like '%/wiki/Talk:%'
order by discussion_length desc- مباحث دربارهی یک مطلب در آدرسی مشابه /wiki/Talk: قرار دارند؛ بههمیندلیل از این عبارت استفاده میکنیم.
مثال ۸: پیداکردن تمامی مقالات ویکیپدیا که لینکی به zoomit.ir دارند
select
url,
css_text_first(content, 'h1#firstHeading') as title
from
pages
where
url_domain = 'wikipedia.org'
and
url like '%/wiki/%'
and
contains_any(content, array['href="https://www.zoomit.ir', 'href="http://www.zoomit.ir', 'href="https://zoomit.ir', 'href="http://zoomit.ir'])دیدگاه شما چیست؟ تجربهی استفاده از این ابزار را داشتهاید؟ ابزارهای دیگری برای تحلیل و استخراج دادهها از ویکیپدیا میشناسید؟ نظرات خود را با ما و کاربران زومیت بهاشتراک بگذارید.
چگونه تمامی تصاویر خود را از اینستاگرام دانلود کنیم؟
هفتهی گذشته، خبری منتشر شد مبنی بر اینکه فیسبوک اطلاعات و آنچه کاربران در این سایت انجام میدهند، با شرکتهای دیگر مانند مایکروسافت و آمازون به اشتراک میگذارد. این موضوع تعدادی از ما را مجبور کرد حساب کاربری فیسبوک و دیگر برنامههای این شرکت مانند اینستاگرام و واتساپ را حذف کنیم (شاید نه برای اولینبار). اگر شما حساب اینستاگرام خود را حذف کنید، تمام تصاویرتان نیز با آن حذف خواهد شد؛ مگر اینکه قبل از حذف حساب کاربری، از آنها پشتیبان تهیه کنید.
مقالههای مرتبط:
بهطور کلی دانلود تصاویر اینستاگرام و تهیه نسخهی پشتیبان از آنها ایدهی خوبی است؛ حتی اگر قصد نداشته باشید این شبکهی اجتماعی را ترک کنید. بااینحال، اگر قصد داشته باشید این سرویس را ترک کنید، این کار تنها راه برای ازدستندادن تصاویر دلخواهتان است. درادامه، مراحل انجام این کار را به شما آموزش میدهیم:
ابتدا وارد برنامهی اینستاگرام شوید و گزینهی پروفایل را از گوشهی پایین سمت راست صفحه انتخاب کنید. در این مرحله، گزینهی منو را از گوشهی بالای سمت راست (به شکل سه خط رویهم) انتخاب و سپس، گزینهی تنظیمات (Settings) را در منوی کشویی لمس کنید.
در اواسط منو بعدی، گزینهای بهنام دانلود دادهها (Data Download) خواهید دید. آن را انتخاب و در صفحهی جدید، ایمیل خود را بررسی کنید. اگر صحیح بود، گزینهی درخواست دانلود (Request Download) را لمس کنید.
دانلود اطلاعات بلافاصله انجام نخواهد شد، درعوض، اینستاگرام وقتی تصاویرتان کاملا آمادهی دانلود شد، ایمیلی برای شما ارسال میکند که حاوی لینک برای دانلود آنها است. این فرایند ممکن است تا ۴۸ ساعت طول بکشد؛ بنابراین، صبور باشید و منتظر ایمیل بمانید.
وقتی تمامی اطلاعات و تصاویر خود را دریافت کردید، آزادانه و بدون نگرانی دربارهی حذفشدن تصاویر دلخواهتان، حساب کاربری خود را میتوانید حذف کنید.
ویکی پدیا و گوگل توافقنامه همکاری امضا کردند
هدف ویکیپدیا این است که دانش را به تمامی افراد جهان برساند؛ اما آنها پذیرفتهاند که اکثریت اطلاعات موجود در این سایت انگلیسی هستند. ازاینرو، ویکیمدیا، شرکت بنیانگذار ویکیپدیا، روز گذشته اعلام کرد که به منظور استفاده از قابلیتهای ترجمهی هوش مصنوعی گوگل، با این شرکت قرارداد همکاری امضا کرده است.
بهموجب این قرارداد، گوگل ترنسلیت بهعنوان ابزار ترجمهی درونی ویکیپدیا به این سایت اضافه خواهد شد و بیهیچ هزینهای بهعنوان یک گزینه درکنار مترجم متنباز اپرتیوم (Apertium) قرار خواهد گرفت. اپرتیوم تا به امروز ۴۰۰ هزار مقاله را ترجمه کرده است. روش انجام کار به شیوهی قبل خواهد بود؛ یعنی مترجم متن، چه گوگل باشد چه اپرتیوم، ابتدا متن را ترجمه میکند و سپس نیروی انسانی بهعنوان ویراستار وارد عمل میشود تا اشتباهات را اصلاح کند.
مقالههای مرتبط:
مدت زیادی بود که ویراستاران ویکیپدیا خواستار اضافه شدن ابزار ترجمهی دیگری مثل گوگل بودند. مترجم گوگل بهلطف بهرهگیری از هوش مصنوعی یکی از پیشرفتهترین ابزارهای مترجم است که ۱۵ زبان بیشتر از اپرتیوم پشتیبانی میکند. این ۱۵ زبان شامل زولو، هوسا، کردی کرمانجی و یوروبا است. این زبانها شاید در سطح جهانی چندان معروف نباشند، اما این مسئله چیزی از اهمیت موضوع برای گویشوران این زبانها کم نمیکند. بهعنوان مثال Zulu، توسط ۱۲ میلیون نفر صحبت میشود؛ اما تنها ۱۰۰۰ مقالهی به این زبان در ویکیپدیا موجود است.
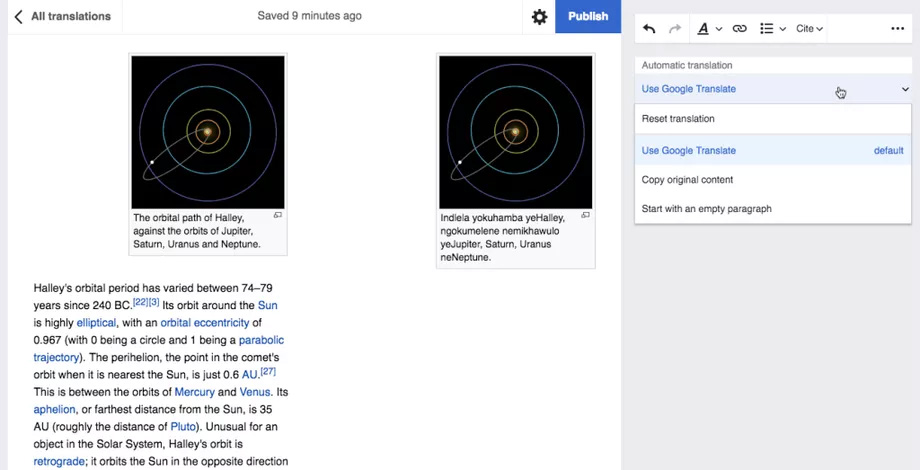
تصویری از ابزار ترجمهی ویکیپدیا به همراه گزینهی ترجمهی گوگل
بنیاد ویکیمدیا در قسمت سؤالات متداول به برخی نگرانیها که ممکن است برای نویسندگان ویکیپدیا پیش بیاید پاسخ داده و اذعان داشته است که هیچگونه دادهی شخصی با گوگل به اشتراک گذاشته نخواهد شد. متون ترجمهشده توسط مترجم گوگل همانند سایر متون ویکیپدیا در دسترس همگان خواهند بود. بهعلاوه هیچگونه برند یا لوگوی گوگل به سایت افزوده نخواهد شد. مدتزمان این توافق تنها یک سال است و پس از آن قابلتمدید خواهد بود؛ هرچند که ویکیمدیا میتواند هرزمان که بخواهد این قرارداد را بههم بزند.
این نکته که ترجمههای انجامشده بهصورت رایگان در دسترس همه خواهند بود، بسیار حائز اهمیت است؛ از این جهت که میتوان از آنها جهت ارتقاء سایر ابزارهای ترجمه از قبیل ابزار متنباز اپرتیوم استفاده کرد. این ایدهی خوبی است که اگر میخواهید دانش را بهصورت رایگان در دسترس مردم قرار دهید، ابزار لازم را به آنها بدهید تا خودشان این کار انجام دهند.
استفاده از Web Font برای مخفی کردن حملات فیشینگ
نفوذگران تکنیک جدیدی را برای مبهمسازی کُدهای صفحات جعلی در طراحی حملات فیشینگ ابداع کردهاند و از Web Fonts بهگونهای استفاده میکنند که پیادهسازی و جایگزینی کُدهای رمزگونه مانند متن ساده به نظر میآید. هنگامی که مرورگر کُدهای صفحات جعلی را ترجمه میکند و برای کاربر نمایش میدهد، کاربر صفحهای را مشاهده میکند که تنها برای دزدیدن اطلاعات شخصی طراحی شده است و کُدگذاری آن بهگونهای توسط توابع خاصی از جاوااسکریپت صورت میگیرد که تشخیص آن سخت است.
مقالههای مرتبط:
استفاده از جایگزینی کاراکترها بهصورت رمزگونه، تکنیک جدیدی بهشمار نمیآید و بازگردانی کُدها و متنها به حالت اولیه توسط سیستمهای خودکار سختی به همراه ندارد. اما نوآوری جدیدی که در این حملات به کار رفته، عدم استفاده از توابع جاوااسکریپت برای جایگزینی بوده و بهجای آن، استفاده از کُدهای CSS است. این حمله فقط با استفاده از دو فونت woff و woff2 که با الگوریتم رمزنگاری base64 مخفی شدهاند، صورت میگیرد. محققان توانایی تشخیص صفحات جعلی را کسب کردهاند که از فونتهای خاص برای ترجمه شدن در مرورگر و نمایش بهصورت متن ساده استفاده میکنند.

طبق گزارش محققان، فونت WOFF باید خروجی استانداردی از حروف الفبا را برای استفاده در صفحات وب فراهم سازد و انتظار میرود توانایی جایگزینی آن با هر یک از حروف الفبا بهصورت کامل امکانپذیر باشد؛ اما مشاهده میکنیم در حملهی فوق، متن مورد استفاده توسط این فونت در صفحه وجود ندارد ولی در مرورگر نمایش داده میشود. همچنین برای فریب بیشتر در این نوع از حملات فیشینگ، نفودگران از فُرمت SVG استفاده میکنند که میتواند ازطریق کُد، کاراکترهای مورد نظر روی مرورگر را به کاربر نمایش دهد و راه تشخیص را سختتر کند.
این روش از ژوئن ۲۰۱۸ توسط نفوذگران در ابزارهای اتوماتیک مخصوص حملات Phishing مورد استفاده قرار گرفته است که محققان در ماه گذشته موفق به کشف آن شدهاند. این نشان میدهد که ممکن است در گذشته فریمورکهای مخرب دیگری برای طراحی حملات فیشینگ این روش استفاده کرده باشند.